本ブログは PyTorch Trace Analysis for the Masses の参考訳です
Anupam Bhatnagar、Xizhou Feng、Brian Coutinho、Yifan Liu、Sung-Han Lin、Louis Feng、Yuzhen Huang著
PyTorchユーザー向けのオープンソース パフォーマンス分析および可視化Pythonライブラリである、Holistic Trace Analysis(HTA)の公開リリースを発表できることを嬉しく思います。HTAは、複雑で解釈が難しいPyTorchプロファイラーによって収集されたKinetoトレースを入力として受け取り、これらのトレースに含まれるパフォーマンス情報をレベルアップします。GPUでの大規模な分散トレーニング ジョブのパフォーマンスの問題を理解し、デバッグするために、Metaの内部で最初に開発されました。学際的なチームは、HTAの機能に多くの機能強化を行い、最先端のMLワークロードをサポートするように拡張しました。
機械学習の研究者やシステムエンジニアは、ワークロードのパフォーマンスのボトルネックを認識していないため、モデルをコンピューターでスケールアップするのに苦労することがよくあります。ジョブに要求されるリソース(GPU、メモリなど)は、「内部」の可視性の欠如により、実際に必要なリソースと一致しないことがよくあります。ハードウェア スタックから最高のパフォーマンスを実現するには、分散トレーニング ワークロードのリソース使用率とボトルネックを理解することが不可欠です。
最初のHTA実装は、Deep Learning Based Recommendation Models(DLRM)を特に対象としていました。HTAの機能を汎用化し、ビジョン モデルやNLPモデルの分析などのユースケースに適用できるようにするために、HTAコードベースをリファクタリングし、ライブラリをより大きなコミュニティで利用できるようにすることにしました。この新しいコードベースには、効率とパフォーマンスの大幅な向上につながるいくつかの重要なアイデアが実装されています。
このブログでは、HTAのオープンソース バージョンに実装されたいくつかの機能を紹介します。これらの機能は、Pythonスクリプトとして使用できるだけでなく、Jupyterノートブックで対話的に使用することもできます。HTAは次の機能を提供します。
1. 次元別内訳
- Temporal:単一ノードおよびすべてのランクでの計算、通信、メモリイベント、およびアイドル時間に費やされた時間に関するGPU時間の内訳。
- Idle Time(アイドル時間):GPUのアイドル時間を、ホストの待機中、別のカーネルの待機中、または不明な原因に起因するものに分類します。
- Kernel:各ランクで期間が最も長いカーネルを見つけます。
- Communication Computation Overlap:通信が計算をオーバーラップしている時間の割合を計算します。
2. 統計分析
- Kernel Duration Distribution:異なるランク間で最長のカーネルにかかった平均時間の分布。
- CUDA Kernel Launch:非常に短い期間、長い期間、および過度の起動時間を持つGPUカーネルのディストリビューション。
- Augmented Counters (Memory bandwidth, Queue length):メモリ コピー帯域幅と各CUDAストリームでの未処理の操作の数に関する洞察を提供する拡張トレースファイル。
3. パターン
- 頻繁なCUDAカーネル:特定のPyTorchまたはユーザー定義のオペレータによって最も頻繁に起動されるCUDAカーネルを見つけます。
4. トレース比較
- Trace Diff:トレース間の違いを特定して視覚化するためのトレース比較ツール。
ユーザーは、HTAソースコードをGithubから入手できます。ユーザーは、上記の機能に加えて、コードベースで提供されるコアライブラリとデータ構造を使用して、新しい機能を要求したり、独自の分析を構築したりできます。
GPUトレーニング パフォーマンスデバッグ 101
分散トレーニング ジョブでのGPUのパフォーマンスを理解するために、モデル オペレータがGPUデバイスとどのようにやり取りするか、およびそのようなやり取りが特定の測定可能なメトリックにどのように反映されるかを検討します。
大まかに言うと、モデル実行におけるGPU操作を3つの大きなカテゴリに分類できます。これ以降、カーネルタイプと呼びます。
- 計算 (COMP) – 計算カーネルは、行列の乗算や同様の数値計算のためにコンパイルされたルーチンを実行します。これらは、モデルの実行に必要なすべての計算処理を担当します。
- 通信 (COMM) – 通信カーネルは、分散トレーニング ジョブで異なるGPUデバイス間でデータを交換および同期する役割を担うルーチンです。NVIDIA Collective Communication Library(NCCL)は広く使用されている通信ライブラリであり、そのすべてのカーネルには接頭辞「nccl」が付いています。NCCLカーネルの例には、NCCL_AllGather、NCCL_ReduceScatter、NCCL_AllReduceなどが含まれます。
- メモリ (MEM) – メモリ カーネルは、GPUデバイス上のメモリの割り当て/割り当て解除、およびホスト上のメモリ空間とGPU間のデータ移動を管理します。メモリ カーネルにはMemcpy_H2D、Memcpy_D2H、Memcpy_D2D、Memsetなどが含まれます。ここで、Hはホストを表し、DはGPUデバイスを表します。したがって、H2D、D2H、D2Dは、それぞれホストからデバイス、デバイスからホスト、デバイスからデバイスを表します。
NVIDIA A100 GPUのような最新のGPUデバイスは、複数のカーネルを同時に実行できる超並列デバイスであるため、計算、通信、およびメモリ カーネルをオーバーラップさせて、モデルの実行時間を短縮することができます。オーバーラップを実現する一般的な手法の1つは、複数のCUDAストリームを利用することです。CUDAストリームは、ホストコードによって発行された順序でGPUデバイス上で実行される一連の操作です。異なるCUDAストリームをインターリーブして同時に実行することもできるため、カーネルのオーバーラップの効果が得られます。
上記の概念を理解するのに役立つように、図1は、1回の反復で8つのGPUでの分散トレーニング ジョブのサンプルにおけるGPUカーネルのタイムラインを示しています。以下の図では、各ランクは1つのGPUを表し、各GPUのカーネルは6つのCUDAストリームで実行されます。図の右側の列には、使用されているGPUカーネルの名前が表示されます。図の中央では、計算カーネルと通信カーネルが重複しています。この図は、HTAで利用可能なplot_timelineサンプル ノートブックを使用して作成されています。
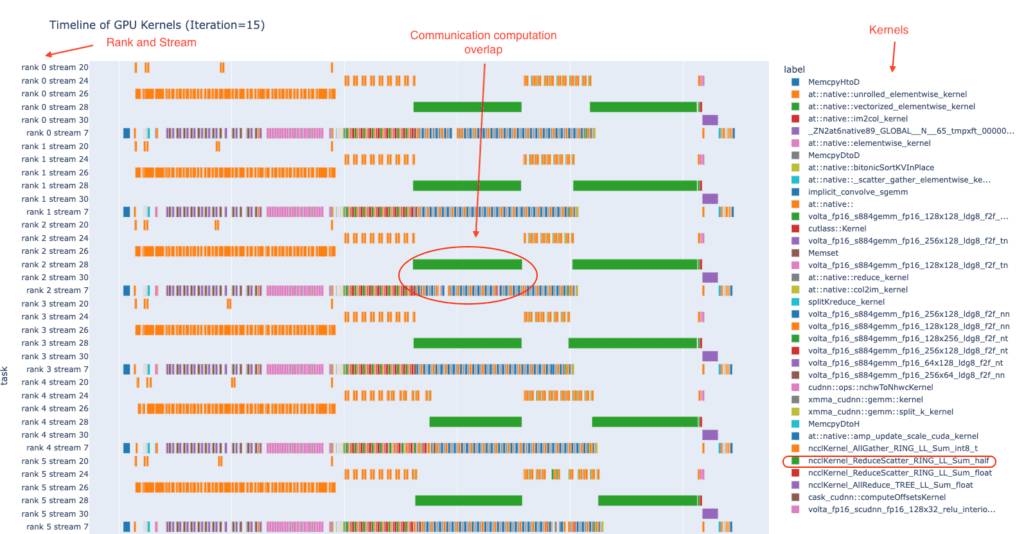
図1:複数のランクにわたるGPUカーネルの実行タイムラインの例
複数のGPUトレーニング ジョブのパフォーマンスは、複数の要因の影響を受けます。これらの要因の中で、モデルの実行によってGPUカーネルがどのように作成および調整されるかが重要な役割を果たします。HTAは、モデルの実行がGPUデバイスとどのように相互作用するかについての洞察を提供し、パフォーマンス向上の機会を強調します。
HTAに組み込まれた機能を使用して、「分散GPUトレーニングの内部で何が起こっているのか」についての洞察をユーザーに提供することを目指しています。これらの機能については、次のいくつかの段落で簡単に説明します。
全体的なトレース分析の機能
ほとんどのユーザーにとって、GPUトレーニング ジョブのパフォーマンスを理解することは簡単ではありません。したがって、このライブラリを構築して、トレース分析のタスクを簡素化し、モデル実行トレースを調べることでユーザーに役立つ洞察を提供します。最初のステップとして、ほとんどのユーザーがこのライブラリの恩恵を受けることができるように、重要で十分に汎用的な機能を開発しました。
時間内訳: まず、GPUが計算、通信、メモリイベントに時間を費やしているのか、それともアイドル状態なのかを尋ねることから始めます。この質問に答えるために、一時的な内訳機能は、これらのカテゴリに関する内訳を提示します。高いトレーニング効率を実現するには、コードで計算カーネルが使用する時間を最大化し、アイドル時間と非計算時間(通信カーネルまたはメモリカーネルが使用する時間)を最小化する必要があります。これは、計算カーネルと通信カーネルまたはメモリカーネルの同時実行を実装することによって実現されます。計算カーネルと通信/メモリカーネルの同時実行中は、通信/メモリカーネルに費やされた時間が計算時間に含まれることに注意してください。
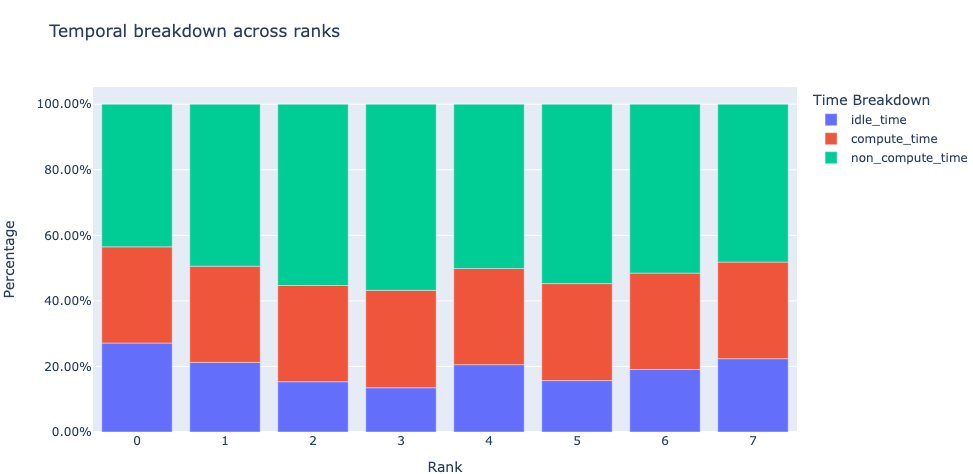
図2:8つのGPUの時間的内訳
カーネルの内訳:どのカーネルが最も多くの時間を費やしているかを尋ねるのは自然なことです。次の機能は、各カーネル タイプ(COMM、COMP、MEM)内で費やされた時間を分類し、期間で並べ替えます。この情報は、カーネルの種類ごと、ランクごとに円グラフで表示されます。下の図3を参照してください。
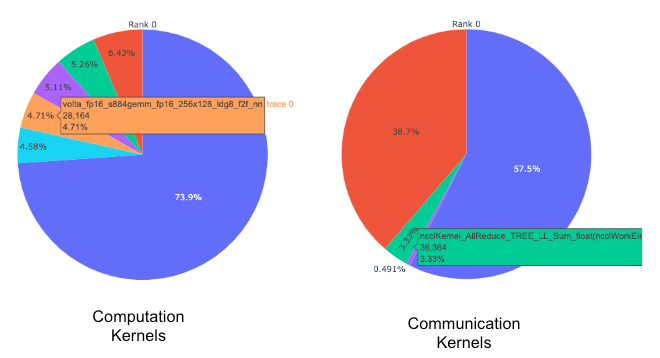
図3:上位の計算および通信カーネルの円グラフ
カーネル期間の分布:続いて、質問することもできます。特定のカーネルについて、ランク全体で費やされた時間の分布はどのようなものですか?これに答えるために、HTAは、すべてのランクにわたる特定のカーネルの平均期間の棒グラフを生成します。さらに、棒グラフのエラーバーは、特定のランクで特定のカーネルにかかった最小時間と最大時間を示します。以下の図4は、他のランクと比較したランク0の平均継続時間の不一致を示しています。ランク0でのこの異常な動作は、可能性のあるバグを探す場所をユーザーに示します。
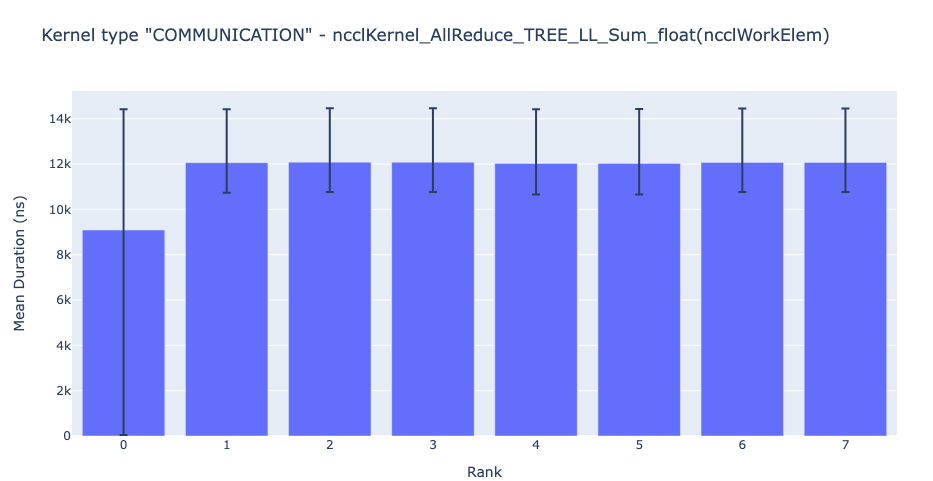 図4:8つのランクにわたるNCCL AllReduceカーネルの平均継続時間
図4:8つのランクにわたるNCCL AllReduceカーネルの平均継続時間
通信計算のオーバーラップ:分散トレーニングでは、複数のGPUデバイス間の通信および同期イベントにかなりの時間が費やされます。高いGPU効率(つまり、TFLOPS/GPU)を実現するには、GPUが実際の計算作業を実行し続けることが不可欠です。つまり、他のGPUからのデータを待機しているためにGPUがブロックされないようにする必要があります。データの依存関係によって計算がブロックされる程度を測定する1つの方法は、計算と通信のオーバーラップを計算することです。通信イベントが計算イベントとオーバーラップすると、GPU効率が高くなります。通信と計算のオーバーラップが不足すると、GPUがアイドル状態になり、効率が低下します。このように、通信計算オーバーラップ機能は、各ランクのジョブで時間通信と計算がオーバーラップする割合を計算し、棒グラフ表現を生成します。下の図を参照してください。より正確には、次の比率を測定します。
(通信時の計算時間)÷(通信時間)
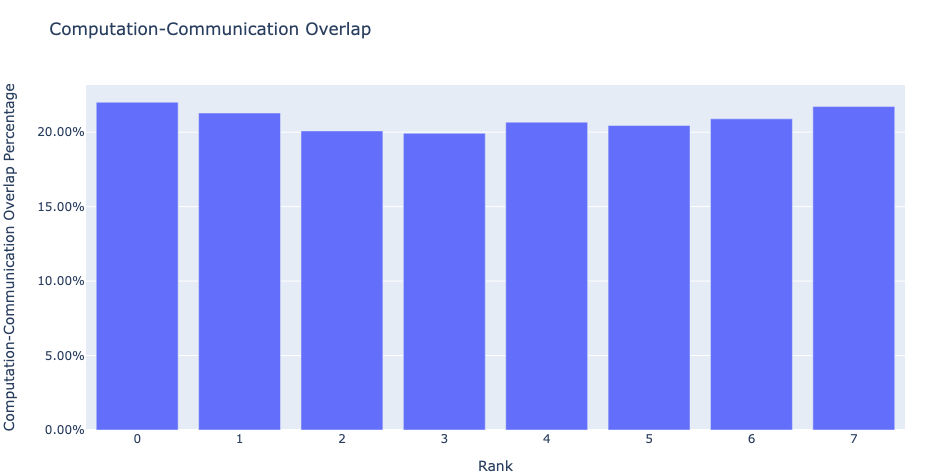 図5:通信計算のオーバーラップ
図5:通信計算のオーバーラップ
拡張カウンター (キューの長さ、メモリ帯域幅):デバッグを支援するために、HTAは、D2H、H2D、およびD2Dメモリコピー(memcpy)およびメモリセット(memset)イベントのメモリ帯域幅統計を計算します。さらに、HTAは、各CUDAストリームで未処理のCUDA操作の数も計算します。これをキューの長さと呼びます。ストリームのキューの長さが 1024以上の場合、そのストリームで新しいイベントをスケジュールできず、GPUイベントが処理されるまでCPUが停止します。さらに、HTAは、メモリ帯域幅とキューの長さの時系列のトラックを含む新しいトレースファイルを生成します。以下の図6を参照してください。
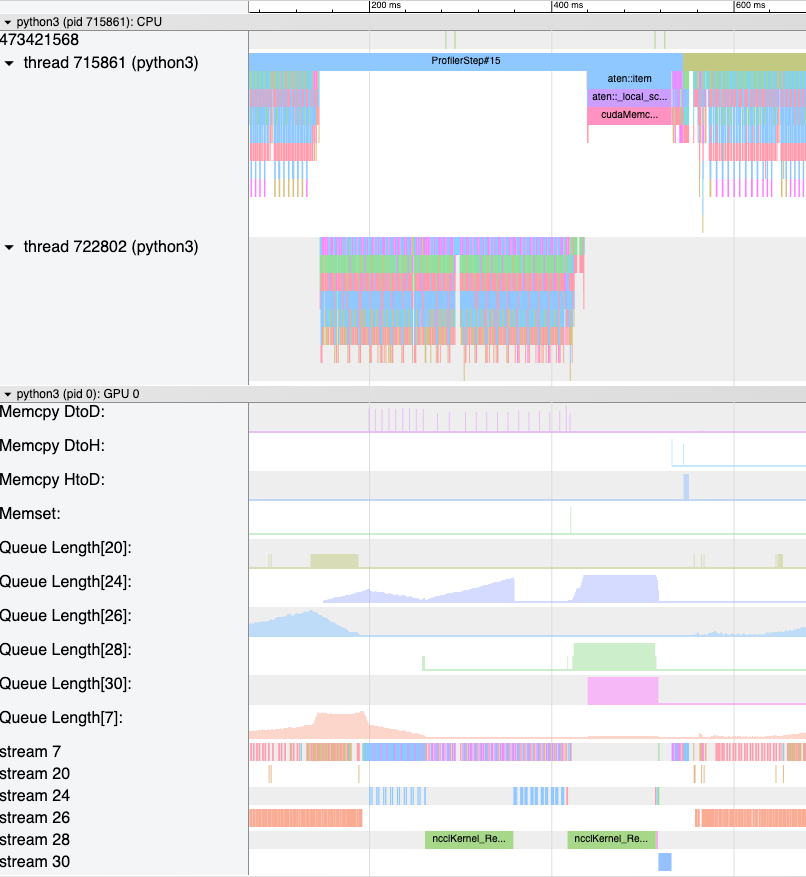
図6:メモリ帯域幅とキューの長さ
これらの主要な機能により、システムのパフォーマンスを垣間見ることができ、「システムで何が起こっているのか?」という答えを得るのに役立ちます。HTAが進化するにつれて、「なぜXが発生するのか?」に対処したいと考えています。また、ボトルネックを克服するための可能な解決策を提案します。
インストールと使い方
インストール
HTAのインストールについては、READMEを参照してください。簡単に言えば、ユーザーはレポを複製し、必要なPythonパッケージをpip経由でインストールする必要があります。
使用法
このバージョンのHolistic Trace Analysisは現在ベータ版であり、JupyterノートブックでHTAを使用することをお勧めします。便宜上、デモノートブックが提供されています。開始するには、Jupyterノートブックにhtaパッケージをインポートし、TraceAnalysisオブジェクトを作成して、正確に2行のコードに進みます。
analyzer = TraceAnalysis(trace_dir = “/trace/folder/path”)
要件
- トレーニングまたは推論ジョブのすべてのトレースファイルは、一意のフォルダーに保存する必要があります。
- jsonまたはgzip形式です json形式。
よくある質問
Q.HTAはどのようにインストールできますか?
リポジトリのルート ディレクトリにあるREADMEを参照してください。
Q.HTAの機能とAPIに関するドキュメントはありますか?
ドキュメントと詳細なAPIは、こちらから入手できます。
Q. 機能Xを実装できますか?
機能が必要とされる範囲と実装に必要な労力のレベルに応じて、機能の開発を検討します。Github Issueを開いて、feature-requestラベルでタグ付けしてください。
Q.コードを変更できますか?
他の人に役立つと思われる場合は、途中でPRを行って送信してください。
Q. PyTorchでトレースを収集するにはどうすればよいですか?
こちらのチュートリアルを参照してください。
Q.HTAは運用規模で使用できますか?
こちらのユースケース スタディをご覧ください。

- 2025年 第1回 OSSセキュリティMeetup ご案内 ー 5月20日 富士通 Yokohama Hub - 2025-04-18
- LINEヤフーがLinux Foundationにゴールドメンバーとして加盟 - 2025-04-15
- パナソニック オートモーティブシステムズが
Linux Foundationにゴールドメンバーとして加盟 - 2025-04-15
